One of the great difficulties surrounding how to batch load texts into RQDA is that the package requires imports from .txt files (Huang, 2018). I recently had an issue with this procedure as I was starting a literature review by way of reviewing abstracts in a .bib format. I had taken abstracts from the EBSCO search engine, and from 'rectangulate()' function in the r7283 package, had transformed a bibtext file into an excel spreadsheet with a tidy display of one row per abstract and citiaton information for 140 empirical articles. While the excel file makes for an easy upload into proprietary software, I had never attempted to batch upload this format of text into RQDA.
That is, until I came across a how-to artifact from an unknown workshop (click the link to find the original set of instructions) (Rstudio pubs, n.d.). The main pieces of help came from the idea that users could take a spreadsheet, list and make as characters each in a series of column cells, and then identify those entries (in this case abstracts) by another column to make a list of entries. These would be batch loaded into RQDA.
Line 16 shows the conversion from the R "data" object towards a list of string characters from the abstract in the original excel sheet. I have identified the "Cite.Key" from the abstracts (back from the original conversion from the r7283::rectangulate() function towards an excel sheet) as the names for cases. This is for a particular reason. After coding the abstracts, when I find something of interest while drafting the literature review, I can simply use the .bib file and the apa.csl file to take the cite key from the abstract, and cite as I write (for more information, look up citations in R markdown). The 'options()' function on line 18 makes sure that RQDA and R do not convert the .bib id number into scientific notation (this way, I can cut and paste and get the citation in R markdown). Finally, the 'names()' function is associated with the Cite.Key information in line 20.
Fig 2. shows the final result with the main toolbar of the project, holding over 100 abstracts is held and ready to be coded. The pane to the right is an example abstract.
That is, until I came across a how-to artifact from an unknown workshop (click the link to find the original set of instructions) (Rstudio pubs, n.d.). The main pieces of help came from the idea that users could take a spreadsheet, list and make as characters each in a series of column cells, and then identify those entries (in this case abstracts) by another column to make a list of entries. These would be batch loaded into RQDA.
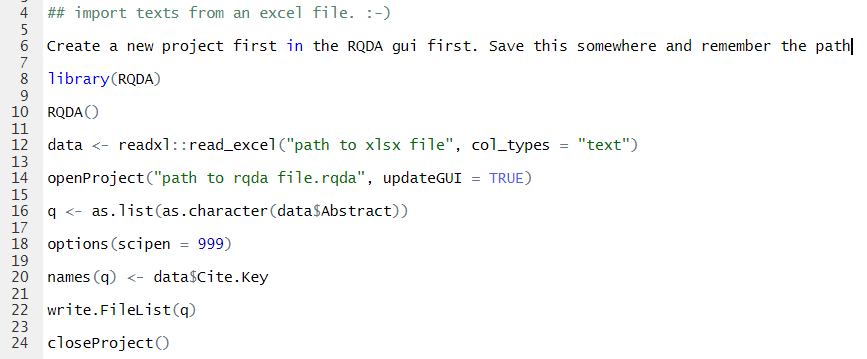 |
| Fig 1. Code from unnamed source to batch import text from excel, with modifications |
Create the new project
While the original file imports from a .csv file, I prefer to import from an .xlsx file as the latter are more stable, particularly with text. In line 6, I comment that the user must first create a new project with RQDA, which requires opening RQDA (see lines 8 and 10), and then clicking on the new project tab, and giving the project a name. I comment in line 6 that the user should save the RQDA new project and remember the path, as it will become important during the process.Prepare the data
The next step involved is reading in the data file from its location along the path that I stored it. I have used Wickham and Bryan's (2019) 'readxl()' function to read in the textual cases as noted on line 12, and then followed the RQDA function 'openProject()' to open the newly created project according to the unnamed, how-to artifact. These two steps constituted the preparation for RQDA receiving the data.Line 16 shows the conversion from the R "data" object towards a list of string characters from the abstract in the original excel sheet. I have identified the "Cite.Key" from the abstracts (back from the original conversion from the r7283::rectangulate() function towards an excel sheet) as the names for cases. This is for a particular reason. After coding the abstracts, when I find something of interest while drafting the literature review, I can simply use the .bib file and the apa.csl file to take the cite key from the abstract, and cite as I write (for more information, look up citations in R markdown). The 'options()' function on line 18 makes sure that RQDA and R do not convert the .bib id number into scientific notation (this way, I can cut and paste and get the citation in R markdown). Finally, the 'names()' function is associated with the Cite.Key information in line 20.
Upload the data
Line 22 is where the action lies. This deceptively simple command takes the object "q", with all of its abstracts, and writes the files to RQDA, where the process of computer assisted qualitative data analysis (CAQDAS) coding can begin. The closeProject() command closes the gateway into the .rqda file that holds all the case information. |
| Fig 2. Abstracts for bib Cite.Key, the final result |
Fig 2. shows the final result with the main toolbar of the project, holding over 100 abstracts is held and ready to be coded. The pane to the right is an example abstract.
References
Hadley Wickham and Jennifer Bryan (2019). readxl: Read Excel Files. R package version 1.3.1.
https://CRAN.R-project.org/package=readxl
Huang, Ronggui. (2018). RQDA: R-based Qualitative Data Analysis. R package version 0.3-1. URL http://rqda.r-forge.r-project.org.
______. (n.d.). Qualitative data analysis with RQDA. http://rstudio-pubs-static.s3.amazonaws.com/2910_c6ec7d53cc37473a81924554bf93b154.html
______. (n.d.). Qualitative data analysis with RQDA. http://rstudio-pubs-static.s3.amazonaws.com/2910_c6ec7d53cc37473a81924554bf93b154.html