Digital Humanities based education Research
This is a backpost from 2017. During that year, I presented my latest work at the 2017 SERA conference in Division II (Instruction, Cognition, and Learning). The title of
This paper accomplished two objectives. First, I engaged previous claims made about the United States' equivalent of high school graduates on the Isle of Sheppey, UK, in the late 1970s. Second, I used emerging digital methods to arrive at conclusions about relationships between unemployment, participants' feelings about their (then) current selves, their possible selves, and their educational accomplishments.
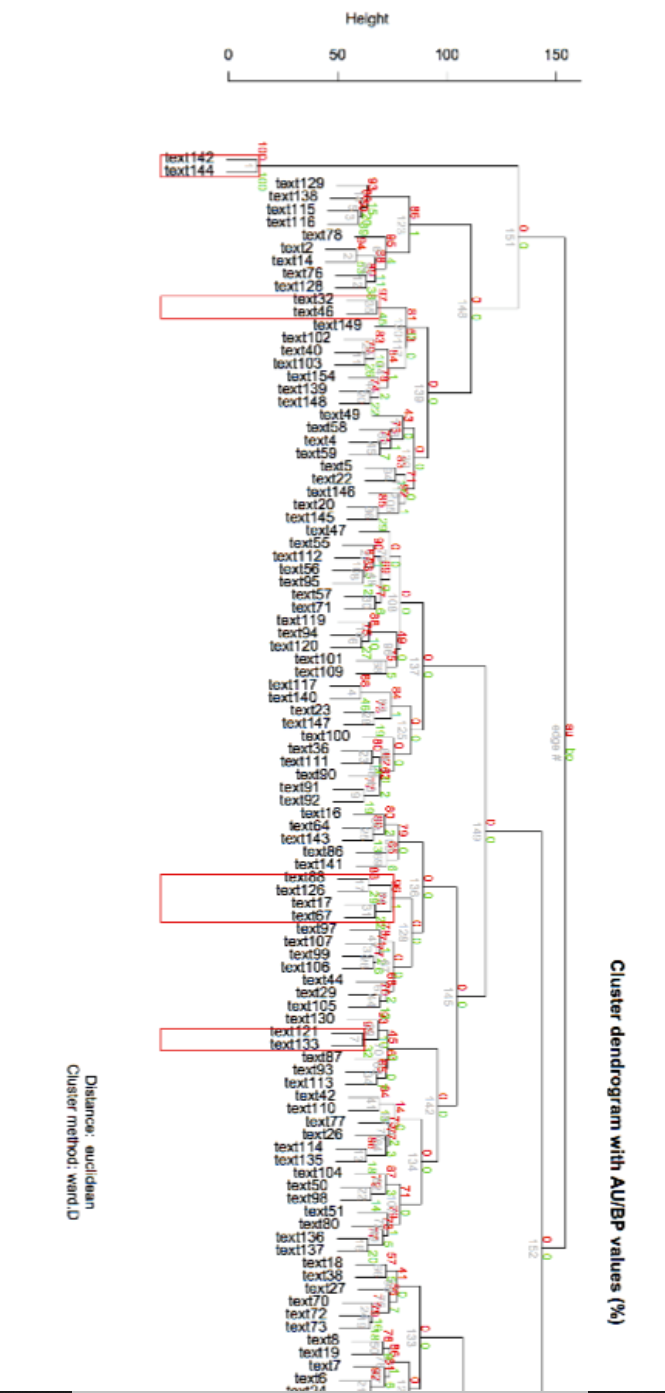
In the image to the left I show a Ward Hierarchical Cluster reflecting the stylometrics of 153 essays (red-boxed p-values indicating statistically significant clusters at p > .05). This goes to answering the question of plagiarism (a question not asked in my 2017 paper). Very little information is available concerning efforts to protect the original Pahl (1978) study's external validity, a question first posed by Lyon et al. (2012). The cluster model homes in on document similarities with high statistical significance. Such models are increasingly possible with the R environment, where statistical learning and automated content analysis are being ushered into a new era.

In the image to the right, I display the median sentiment scores (measured on a scale of positive/negative) in the essays of three age groups (15, 16, 17+) of participants in the Pahl (1978) study. This is again, a question not explored in the upcoming paper, but rather, a snapshot of how the median scores differ across age groups. In interpreting the display of medians, the essay evidence points to those participants who left school at a later age worrying about the availability of future work as highly trained professionals. This reading is supported by cases that describe increased competition in the labor market necessitating the delay of work entry combined with the stress of passing O-levels with high marks for increased opportunity. At issue is whether taking the extra time for studies payed off monetarily. This doubt is seen in the lower sentiment scores among the 17+ group. In contrast, the 16 age group described the prospects of getting out into the workforce and beginning their lives post-schooling. The slightly higher scores reflect some of this meaning contained in the 16 age group essays. Finally, the single case of a 15 year old student reflects the data as it was collected in 1978, recalling that the present one is a descriptive study. This kind of fine grain microanalysis is possible through the combined use of digital research methods such as concordances and sentiment analysis.
The skills involved in parsing text and arriving at conclusions to educational research questions are complex, interdisciplinary, and hold the potential for creating novel algorithms that assist the assessment of writing at multiple grade levels. To flesh out this last idea, I am currently working with a Machine Learning-based classification algorithm. An important component of the work is obtaining a large data set of student essays to work upon so that the algorithm "teaches" itself.
References
Cheon, J. Lee, S., Smith, W., Song, J., & Kim, Y.. (2013). The Determination of Children's Knowledge of Global Lunar Patterns from Online Essays Using Text Mining Analysis. Research In Science Education, 43(2), 667-686. Retrieved from http://dx.doi.org/10.1007/s11165-012-9282-5
Lyon, D., Morgan Brett, B., & Crow, G. (2012). Working with material from the sheppey archive. The International Journal of Social Research Methodology, 15(4), 301 - 309. Retrieved from http://dx.doi.org/10.1080/13645579.2012.688314
Pahl, R. (1984). School leavers study, 1978. [data collection]. 2nd edition. UK Data Service. SN 4867.
|